第一章 单元测试
1、 问题: 为保证形式化系统的有效性,下面哪个选项不是形式化系统需要具有的性质( )
选项:
A:完备性
B:可靠性
C:一致性
D:可判定性
答案: 【
可靠性
】
2、 问题: Deepmind研制的AlphaGo算法没有使用哪个人工智能方法( )
选项:
A:强化学习
B:深度学习
C:蒙特卡洛树搜索
D:逻辑推理
答案: 【
逻辑推理
】
3、 问题: 图灵奖获得者Judea Pearl将推理按照由易到难程度分成三个层次( )
选项:
A:干预、关联、反事实
B:关联、干预、反事实
C:反事实、干预、关联
D:关系、干预、反事实
答案: 【
关联、干预、反事实
】
4、 问题: 以下哪一种算法不属于监督学习算法( )
选项:
A:隐马尔科夫链
B:支持向量机
C:聚类
D:决策树
答案: 【
聚类
】
5、 问题: 以下哪种学习方法的学习目标是学习同一类数据的分布模式( )
选项:
A:监督学习
B:无监督学习
C:强化学习
D:博弈对抗
答案: 【
无监督学习
】
第二章 单元测试
1、 问题:
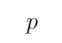 和
和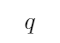 均是原子命题,“如果
均是原子命题,“如果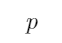 那么
那么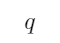 ”是由
”是由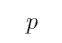 和
和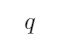 组合得到的复合命题。下面对“如果
组合得到的复合命题。下面对“如果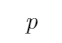 那么
那么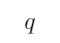 ”这一复合命题描述不正确的是( )
”这一复合命题描述不正确的是( )
选项:
A:
“如果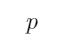 那么
那么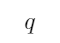 ”定义的是一种蕴涵关系(即充分条件)
”定义的是一种蕴涵关系(即充分条件)
B:
“如果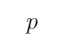 那么
那么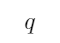 ”意味着命题
”意味着命题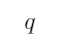 包含着命题
包含着命题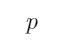 ,即
,即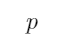 是
是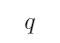 的子集
的子集
C:
无法用真值表来判断“如果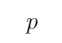 那么
那么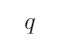 ”的真假
”的真假
D:
当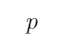 不成立时,“如果
不成立时,“如果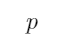 那么
那么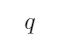 ”恒为真
”恒为真
答案: 【
无法用真值表来判断“如果那么”的真假
】
2、 问题:
下面哪个逻辑等价关系是不成立的( )
选项:
A:

B:

C:

D:

答案: 【
】
3、 问题: 下面对一阶归纳推理(FOIL)中信息增益值(information gain)阐释不正确的是( )
选项:
A:信息增益值用来判断向推理规则中所加入前提约束谓词的质量
B:在算法结束前,每次向推理规则中加入一个前提约束谓词,该前提约束谓词得到的新推理规则具有最大的信息增益值。
C:在计算信息增益值过程中,需要利用所得到的新推理规则和旧推理规则分别涵盖的正例和反例数目
D:信息增益值大小与背景知识样例数目直接相关
答案: 【
信息增益值大小与背景知识样例数目直接相关
】
4、 问题: 下面哪个描述的问题不属于因果分析的内容( )
选项:
A:如果商品价格涨价一倍,预测销售量(sales)的变化
B:如果广告投入增长一倍,预测销售量(sales)的变化
C:如果放弃吸烟,预测癌症(cancer)的概率
D:购买了一种商品的顾客是否会购买另外一种商品
答案: 【
购买了一种商品的顾客是否会购买另外一种商品
】
5、 问题:
判断下列句子是命题( )
选项:
A:x>2。
B:今天的天气真好啊!
C:浙江大学始创于1897年。
D:y < 10。
答案: 【
浙江大学始创于1897年。
】
第三章 单元测试
1、 问题: 以下关于用搜索算法求解最短路径问题的说法中,不正确的是( )。
选项:
A:给定两个状态,可能不存在两个状态之间的路径;也可能存在两个状态之间的路径,但不存在最短路径(如考虑存在负值的回路情况)。
B:假设状态数量有限,当所有单步代价都相同且大于0时,深度优先的图搜索是最优的。
C:假设状态数量有限,当所有单步代价都相同且大于0时,广度优先的图搜索是最优的。
D:图搜索算法通常比树搜索算法的时间效率更高。
答案: 【
假设状态数量有限,当所有单步代价都相同且大于0时,深度优先的图搜索是最优的。
】
2、 问题: 以下关于启发函数和评价函数的说法中正确的是( )。
选项:
A:启发函数不会过高估计从当前节点到目标结点之间的实际代价。
B:取值恒为0的启发函数必然是可容的。
C:评价函数通常是对当前节点到目标节点距离的估计。
D:如果启发函数满足可容性,那么在树搜索A算法中节点的评价函数值按照扩展顺序单调非减;启发函数满足一致性时图搜索A算法也满足该性质。
答案: 【
如果启发函数满足可容性,那么在树搜索A算法中节点的评价函数值按照扩展顺序单调非减;启发函数满足一致性时图搜索A算法也满足该性质。
】
3、 问题: 假如可以对围棋的规则做出如下修改,其中哪个修改方案不影响使用本章介绍的Minimax算法求解该问题?( )
选项:
A:由双方轮流落子,改为黑方连落两子后白方落一子。
B:双方互相不知道对方落子的位置。
C:由两人对弈改为三人对弈。
D:终局时黑方所占的每目(即每个交叉点)计1分,且事先给定了白方在棋盘上每个位置取得一目所获取的分数,假设这些分数各不相同。双方都以取得最高得分为目标。
答案: 【
由双方轮流落子,改为黑方连落两子后白方落一子。
】
4、 问题: 下列关于探索与利用的说法中,不正确的是( )。
选项:
A:在多臂赌博机问题中,过度探索会导致算法很少主动去选择比较好的摇臂。
B:在多臂赌博机问题中,过度利用可能导致算法对部分臂膀额奖励期望估计不准确。
C:在贪心算法中,
的值越大,表示算法越倾向于探索。
D:在多臂赌博机问题中,某时刻UCB1算法选择的臂膀置信上界为,则此时任意摇动一个臂膀,得到的硬币数量不会超过
。
答案: 【
在多臂赌博机问题中,某时刻UCB1算法选择的臂膀置信上界为,则此时任意摇动一个臂膀,得到的硬币数量不会超过
。
】
5、 问题: 下列关于蒙特卡洛树搜索算法的说法中,不正确的是( )。
选项:
A:选择过程体现了探索与利用的平衡。
B:算法进入扩展步骤时,当前节点的所有子节点必然都未被扩展。
C:模拟步骤采取的策略与选择步骤不一定要相同。
D:反向传播只需要更新当前路径上已被扩展的节点。
答案: 【
算法进入扩展步骤时,当前节点的所有子节点必然都未被扩展。
】
第四章 单元测试
1、 问题: 线性判别分析是在最大化类间方差和类内方差的比值( )
选项:
A:对
B:错
答案: 【
对
】
2、 问题: 在一个监督学习任务中,每个数据样本有4个属性和一个类别标签,每种属性分别有3、2、2和2种可能的取值,类别标签有3种不同的取值。请问可能有多少种不同的样本?(注意,并不是在某个数据集中最多有多少种不同的样本,而是考虑所有可能的样本)( )
选项:
A:3
B:6
C:12
D:24
E:48
F:72
答案: 【
72
】
3、 问题: 以下哪种方法不属于监督学习方法( )
选项:
A:聚类
B:决策树
C:线性回归
D:朴素贝叶斯
答案: 【
聚类
】
4、 问题: 无监督学习需要使用到数据的人工标签( )
选项:
A:对
B:错
答案: 【
错
】
5、 问题: 在Adaboosting的迭代中,从第t轮到第t+1轮,某个被错误分类样本的惩罚被增加了,可能因为该样本( )
选项:
A:被第t轮训练的弱分类器错误分类
B:被第t轮后的集成分类器(强分类器)错误分类
C:被到第t轮为止训练的大多数弱分类器错误分类
D:其他选项都正确
答案: 【
被第t轮训练的弱分类器错误分类
】
第五章 单元测试
1、 问题: 可以从最小化每个类簇的方差这一视角来解释K均值聚类的结果,下面对这一视角描述不正确的是( )
选项:
A:最终聚类结果中每个聚类集合中所包含数据呈现出来差异性最小
B:每个样本数据分别归属于与其距离最近的聚类质心所在聚类集合
C:每个簇类的方差累加起来最小
D:每个簇类的质心累加起来最小
答案: 【
每个簇类的质心累加起来最小
】
2、 问题: 下面对相关性(correlation)和独立性(independence)描述不正确的是( )
选项:
A:如果两维变量线性不相关,则皮尔逊相关系数等于0
B:如果两维变量彼此独立,则皮尔逊相关系数等于0
C:“不相关”是一个比“独立”要强的概念,即不相关一定相互独立
D:独立指两个变量彼此之间不相互影响
答案: 【
“不相关”是一个比“独立”要强的概念,即不相关一定相互独立
】
3、 问题: 下面对主成分分析的描述不正确的是( )
选项:
A:主成分分析是一种特征降维方法
B:主成分分析可保证原始高维样本数据被投影映射后,其方差保持最大
C:在主成分分析中,将数据向方差最大方向进行投影,可使得数据所蕴含信息没有丢失,以便在后续处理过程中各个数据“彰显个性”
D:在主成分分析中,所得低维数据中每一维度之间具有极大相关度
答案: 【
在主成分分析中,所得低维数据中每一维度之间具有极大相关度
】
4、 问题: 下面对特征人脸算法描述不正确的是( )
选项:
A:特征人脸方法是一种应用主成分分析来实现人脸图像降维的方法
B:特征人脸方法是用一种称为“特征人脸(eigenface)”的特征向量按照线性组合形式来表达每一张原始人脸图像
C:每一个特征人脸的维数与原始人脸图像的维数一样大
D:特征人脸之间的相关度要尽可能大
答案: 【
特征人脸之间的相关度要尽可能大
】
5、 问题: 在潜在语义分析中,给定M个单词和N个文档所构成的单词-文档矩阵(term-document)矩阵,对其进行分解,将单词或文档映射到一个R维的隐性空间。下面描述不正确的是( )
选项:
A:单词和文档映射到隐性空间后具有相同的维度
B:通过矩阵分解可重建原始单词-文档矩阵,所得到的重建矩阵结果比原始单词-文档矩阵更好捕获了单词-单词、单词-文档、文档-文档之间的隐性关系
C:这一映射过程中需要利用文档的类别信息
D:隐性空间维度的大小由分解过程中所得对角矩阵中对角线上不为零的系数个数所决定
答案: 【
这一映射过程中需要利用文档的类别信息
】
第六章 单元测试
1、 问题: 下面对误差反向传播 (error back propagation, BP)描述不正确的是( )
选项:
A:BP算法是一种将输出层误差反向传播给隐藏层进行参数更新的方法
B:BP算法将误差从后向前传递,获得各层单元所产生误差,进而依据这个误差来让各层单元修正各单元参数
C:对前馈神经网络而言,BP算法可调整相邻层神经元之间的连接权重大小
D:在BP算法中,每个神经元单元可包含不可偏导的映射函数
答案: 【
在BP算法中,每个神经元单元可包含不可偏导的映射函数
】
2、 问题: 以下关于梯度下降和随机梯度下降的说明,哪些描述是正确的( )
选项:
A:在梯度下降和随机梯度下降中,为了最小化损失函数,通常使用循环迭代的方式不断更新模型参数;
B:在每次迭代中,随机梯度下降需要计算训练集所有样本的误差和,用于更新模型参数;
C:在每次迭代中,梯度下降使用所有数据或者部分训练数据,用于更新模型参数.
D:梯度下降是遗传算法的一种参数优化算法
答案: 【
在梯度下降和随机梯度下降中,为了最小化损失函数,通常使用循环迭代的方式不断更新模型参数;
在每次迭代中,梯度下降使用所有数据或者部分训练数据,用于更新模型参数.
】
3、 问题: 关于sigmoid激活函数,下列描述正确的是( )
选项:
A:它是凸函数,凸函数无法解决非凸问题;
B:它可以有负值;
C:它无法配合交叉熵损失函数使用;
D:当输入值过大或者过小时,梯度趋近于0,容易造成梯度消失问题。
答案: 【
当输入值过大或者过小时,梯度趋近于0,容易造成梯度消失问题。
】
4、 问题: 下面对前馈神经网络这种深度学习方法描述不正确的是( )
选项:
A:是一种端到端学习的方法
B:是一种监督学习的方法
C:实现了非线性映射
D:隐藏层数目大小对学习性能影响不大
答案: 【
隐藏层数目大小对学习性能影响不大
】
5、 问题: 激活函数的引入和增强模型的非线性拟合能力。( )
选项:
A:对
B:错
答案: 【
对
】
第七章 单元测试
1、 问题: 下面对强化学习、监督学习和深度卷积神经网络学习的描述正确的是( )
选项:
A:评估学习方式、有标注信息学习方式、端到端学习方式
B:有标注信息学习方式、端到端学习方式、端到端学习方式
C:评估学习方式、端到端学习方式、端到端学习方式
D:无标注学习、有标注信息学习方式、端到端学习方式
答案: 【
评估学习方式、有标注信息学习方式、端到端学习方式
】
2、 问题: 在强化学习中,通过哪两个步骤的迭代,来学习得到最佳策略( )
选项:
A:价值函数计算与动作-价值函数计算
B:动态规划与Q-Learning
C:贪心策略优化与Q-learning
D:策略优化与策略评估
答案: 【
策略优化与策略评估
】
3、 问题: 在强化学习中,哪个机制的引入使得强化学习具备了在利用与探索中寻求平衡的能力( )
选项:
A:贪心策略
B:蒙特卡洛采样
C:动态规划
D:贝尔曼方程
答案: 【贪心策略
】
4、 问题: 与马尔可夫奖励过程相比,马尔可夫决策过程引入了哪一个新的元素( )
选项:
A:反馈
B:动作
C:终止状态
D:概率转移矩阵
答案: 【
动作
】
5、 问题: 在本章内容范围内,“在状态,按照某个策略行动后在未来所获得回报值的期望”,这句话描述了状态
的( B );“在状态
,按照某个策略采取动作
后在未来所获得回报值的期望”,这句话描述了状态
的( )
选项:
A:策略优化
B:价值函数
C:动作-价值函数
D:采样函数
答案: 【
动作-价值函数
】
第八章 单元测试
1、 问题: 标志着现代博弈理论的初步形成的事件是( )
选项:
A:1944年冯·诺伊曼与奥斯卡·摩根斯特恩合著《博弈论与经济行为》的出版
B:纳什均衡思想的提出
C:囚徒困境思想的提出
D:冯·诺伊曼计算机的实现
答案: 【
1944年冯·诺伊曼与奥斯卡·摩根斯特恩合著《博弈论与经济行为》的出版
】
2、 问题:下面对博弈研究分类不正确的是( )
选项:
A:合作博弈与非合作博弈
B:静态博弈与动态博弈
C:完全信息博弈与不完全信息博弈
D:囚徒困境与纳什均衡
答案: 【
囚徒困境与纳什均衡
】
3、 问题:下面对纳什均衡描述正确的是( )
选项:
A:参与者所作出的这样一种策略组合,在该策略组合上,任何参与者单独改变策略都不会得到好处。
B:在一个策略组合上,当所有其他人都改变策略时,也无法破坏先前的博弈平衡,则该策略组合就是一个纳什均衡。
C:参与者所作出的这样一种策略组合,在该策略组合上,若干参与者改变策略后,大家都不会得到更多好处。
D:参与者所作出的这样一种策略组合,在该策略组合上,有且只有1个参与者改变策略后,其收益会增加。
答案: 【
参与者所作出的这样一种策略组合,在该策略组合上,任何参与者单独改变策略都不会得到好处。
】
4、 问题:下面对混合策略纳什均衡描述正确的是( )
选项:
A:博弈过程中,博弈方通过概率形式随机从可选策略中选择一个策略而达到的纳什均衡被称为混合策略纳什均衡。
B:博弈过程中,博弈方通过非概率形式随机从可选策略中选择一个策略而达到的纳什均衡被称为混合策略纳什均衡。
C:博弈过程中,博弈方以概率形式随机从可选收益中选择一个收益,而达到的纳什均衡被称为混合策略纳什均衡。
D:博弈过程中,博弈方以非概率形式随机从可选收益中选择一个收益,而达到的纳什均衡被称为混合策略纳什均衡。
答案: 【
博弈过程中,博弈方通过概率形式随机从可选策略中选择一个策略而达到的纳什均衡被称为混合策略纳什均衡。
】
5、 问题: 在遗憾最小化算法中,玩家i按照如下方法来计算其在每一轮产生的悔恨值( )
选项:
A:其他玩家策略不变,只改变玩家i的策略后,所产生的收益之差。
B:所有玩家策略均改变,所产生的收益之差。
C:至少改变1个以上玩家的策略, 所产生的收益之差。
D:每个玩家策略不变,只改变收益函数,所产生的收益之差。
答案: 【
其他玩家策略不变,只改变玩家i的策略后,所产生的收益之差。
】
第九章 单元测试
1、 问题: 关于类脑计算下列说法正确的是( )
选项:
A:类脑计算可以完全替代冯• 诺依曼计算结构
B:类脑计算完全依赖现有的冯• 诺依曼计算结构
C:类脑计算芯片是一种人工智能计算芯片
D:类脑计算要复制人类大脑或建造一种模拟神经元功能的芯片
答案: 【
类脑计算芯片是一种人工智能计算芯片
】
2、 问题: 面向人工智能的非冯诺依曼计算架构主要聚焦( )
选项:
A:计算
B:内存和存储
C:智能
D:通讯
答案: 【
内存和存储
】
3、 问题: 评价人工智能芯片的指标包括( )
选项:
A:低延迟和隐私性
B:低延迟和高吞吐量
C:低延迟和安全性
D:高吞吐量和安全性
答案: 【
低延迟和高吞吐量
】
4、 问题: 建设人工智能生态所需的重中之重是( )
选项:
A:人工智能算法框架或平台研制
B:人工智能模型和算法
C:推动数据共享、有机协调存算能力
D:加快人工智能在各领域的应用
答案: 【
人工智能算法框架或平台研制
】
5、 问题: 人工智能伦理不关注一下哪个社会形态应该需要遵守的道德准则( )
选项:
A:人-机
B:机-机
C:人-机共融
D:人-人
答案: 【
人-人
】
第十章 单元测试
1、 问题: 下面哪项不属于图片预处理( )
选项:
A:图像解码
B:卷积和池化
C:调整图片大小
D:归一化
答案: 【
卷积和池化
】
2、 问题: MindSpore的总体框架主要包含4个部分,下列哪项不属于MindSpore的总体框架( )
选项:
A:扩展层
B:前端表达层
C:编译优化层
D:网络模型库
答案: 【
网络模型库
】
3、 问题: 下列关于MindSpore描述错误的是( )
选项:
A:MindSpore采用基于源码转换的自动微分机制将控制流表示为复杂的组合
B:MindSpore只支持静态图,更易于构建模型架构
C:MindSpore可以实现数据并行和模型并行
D:MindSpore可以用于训练大模型
答案: 【
MindSpore只支持静态图,更易于构建模型架构
】
4、 问题: 下面描述正确的是( )
选项:
A:卷积算子主要用于提取特征
B:Softmax主要用于提取特征
C:池化算子主要用于提取特征
D:归一化操作主要用于提取特征
答案: 【
卷积算子主要用于提取特征
】
5、 问题: 下列关于神经网络训练的正确顺序是( )
选项:
A:反向传播-前向传播-更新权重-清除梯度
B:前向传播-更新权重-反向传播-清除梯度
C:前向传播-反向传播-更新权重-清除梯度
D:反向传播-更新权重-前向传播-清除梯度
答案: 【
前向传播-反向传播-更新权重-清除梯度
】

答案")



还木有评论哦,快来抢沙发吧~